
Les métriques d’autorité SEO sont plein de choses, mais ce qu’elles ne sont pas, ce sont des valeurs absolues à exploiter sur une échelle, sans contexte.
Aujourd’hui, j’aimerais vous montrer ce qui me semble être la meilleure approche pour utiliser des métriques SEO, et bien sûr, on va faire ça avec les meilleures métriques, celles de Babbar.
Je vais quand même faire ça avec un peu de recul en vous disant quelles métriques utiliser et pourquoi, puis comment il faut utiliser ces métriques, et enfin nous finirons sur un peu de code pour automatiser tout ça avec Babbar.
Quelles métriques utiliser ?
Il y a beaucoup de métriques d’autorité à exploiter en SEO. Commençons par l’essentiel :
La seule métrique d’autorité calculée utilisée par Google est le PageRank. Le Trust Rank est une tentative de Yahoo d’améliorer une approche de votes par des liens, mais ce n’est pas utilisé par Google et ne peut donc pas expliquer le ranking sur Google.
On va donc se baser sur les métriques d’autorité basées sur le PageRank.
Petite information complémentaire : la formule du PageRank est une formule itérative avec un potentiel de cycles dans ses graphes de liens, potentiel restreint parce que l’algorithme est conçu pour gérer ces cycles en convergeant vers des résultats stables. Dans le graphe des liens, chaque page est un nœud, recevant et envoyant des liens, le PageRank évalue donc la puissance de chaque page, grâce aux liens qui sont réalisés.
Vous n’avez rien compris ? Je vous rassure, c’est sans doute que je m’exprime mal.
Pour calculer le PageRank de chaque page, il faut avoir l’intégralité des liens et des pages du web en mémoire.
Parce qu’on peut créer des boucles (linkwheels) dans le graphe, on a plus intérêt à faire des liens sortants depuis son site que ne pas en faire (votre page revient dans le chemin potentiel du PageRank). (je suis d’accord, ça n’a rien à voir avec le reste mais il faut le dire).
Le PageRank d’une page n’a pour usage que d’être comparé aux autres urls existantes pour déterminer sa place dans l’immensité du web, afin de définir si pour une pertinence sémantique égale, cette page vaut mieux ou moins bien que les autres. Il faut donc ainsi utiliser des métriques qui calculent les métriques des urls avant de les agréger au niveau site.
Quelles métriques correspondent donc à ces critères ?
Du côté de chez Babbar :
– La Page Value (agrégée en Host Value)
– La Semantic Value (son agrégation en host a le même nom)
– Le Babbar Authority Score (pareil, même nom en host et en url)
– Le Scholar Score
Du côté de chez Ahrefs :
– URL Rating (agrégé en Domain Rating)
Du côté de chez Moz :
– Page Authority (agrégé en Domain Authority)
Du côté de chez Semrush :
Aucune : Authority Score n’est pas une métrique de PageRank
Du côté de chez Majestic :
Aucune : le Trust n’est pas une métrique Google. Le Citation n’est pas calculé par url.
Quelles autres métriques peut on utiliser ?
En réalité, il y a 2 autres métriques intéressantes : le nombre de liens entrants, et le nombre de sites référents. Normalement, tous les outils sérieux vous fournissent ces informations.
Comment les utiliser ?
Une métrique d’autorité (hors nombre de liens et nombre de sites référents) sont généralement sur une base 100. Cela vous permet de comparer votre site ou votre page et son autorité relative à celles des concurrents, qui sont jugées sur les mêmes critères.
Et… C’est exactement comme ça qu’il faut les utiliser. Ce n’est pas grave si vous n’êtes pas à 100%, tant que vous êtes au dessus de vos concurrents !
Donc comment utiliser les métriques d’autorité en SEO ? En les comparant à vos concurrents, tout simplement.
Voilà, c’est tout, bonne journée !
Non, plus sérieusement : Comparer vos métriques avec celles des concurrents a un autre intérêt : lorsqu’un outil fait une mise à jour, le classement entre votre site et ceux des concurrents ne change pas : les meilleurs restent meilleurs.
Et voilà pourquoi je vous propose le code (dans la partie suivante) qui suit ce point de vue pour le rendre visuel.
J’ai fait un script assez simple, qui vous permet de renseigner plusieurs sites, et qui récupère l’historique des métriques d’autorité voulues pour chacun de ces sites. Vous obtenez ensuite un graphique qui va vous permettre de comparer votre site à celui des concurrents.
Si vous voulez éviter la question sur le score qui augmente ou baisse lors de la mise à jour de l’outil, le plus simple est d’afficher selon le rang du site en fonction du score.
Le code
Tout d’abord, vous aurez besoin des packages suivants (et donc de lancer les commandes suivantes) :
pip install git+https://github.com/BabbarTech/BabbarPy.git
pip install configparser, pandas, numpy, plotlyEt enfin, le code :
import csv
from BabbarPy.host import h_history
import os
import configparser
import pandas as pd
import numpy as np
import plotly.express as px
import plotly.graph_objects as go
def create_hosts_list():
hosts = []
while True:
host = input("Veuillez entrer le host à vérifier (ou appuyez sur entrée pour terminer) : ")
if host == '':
break
hosts.append(host)
with open('hosts.txt', 'w') as f:
for host in hosts:
f.write(f"{host}\n")
def get_api_key():
config = configparser.ConfigParser()
if not os.path.exists('config.ini') or not config.read('config.ini') or not 'API' in config or not 'api_key' in config['API']:
api_key = input("Entrez votre clé API: ")
config['API'] = {'api_key': api_key}
with open('config.ini', 'w') as configfile:
config.write(configfile)
return api_key
else:
return config['API']['api_key']
def convert_scholar_score(score):
score_map = {
'A+': 13, 'A': 12, 'A-': 11,
'B+': 10, 'B': 9, 'B-': 8,
'C+': 7, 'C': 6, 'C-': 5,
'D+': 4, 'D': 3, 'D-': 2,
'F': 1
}
return score_map.get(score, np.nan)
def plot_metrics(csv_file):
# Read the CSV file into a DataFrame
df = pd.read_csv(csv_file, parse_dates=['Date'])
df.set_index('Date', inplace=True)
# Separate the data into two DataFrames for each metric
bas_df = df[[col for col in df.columns if 'bas_' in col]]
scholar_df = df[[col for col in df.columns if 'scholar_' in col]]
# Ensure all data is numeric and handle missing values
bas_df = bas_df.apply(pd.to_numeric, errors='coerce')
scholar_df = scholar_df.apply(pd.to_numeric, errors='coerce')
# Plot the Babbar Authority Scores using Plotly
fig_bas = go.Figure()
for column in bas_df.columns:
fig_bas.add_trace(go.Scatter(x=bas_df.index, y=bas_df[column], mode='lines+markers', name=column))
fig_bas.update_layout(
title='Comparison of Babbar Authority Scores Over Time',
xaxis_title='Date',
yaxis_title='Babbar Authority Score',
hovermode='x'
)
fig_bas.write_html("babbar_authority_scores.html")
# Plot the Scholar Scores using Plotly
fig_scholar = go.Figure()
for column in scholar_df.columns:
fig_scholar.add_trace(go.Scatter(x=scholar_df.index, y=scholar_df[column], mode='lines+markers', name=column))
fig_scholar.update_layout(
title='Comparison of Scholar Scores Over Time',
xaxis_title='Date',
yaxis_title='Scholar Score',
hovermode='x'
)
fig_scholar.write_html("scholar_scores.html")
def plot_ranked_metrics(csv_file):
# Read the CSV file into a DataFrame
df = pd.read_csv(csv_file, parse_dates=['Date'])
df.set_index('Date', inplace=True)
# Separate the BAS data
bas_df = df[[col for col in df.columns if 'bas_' in col]]
# Ensure all data is numeric and handle missing values
bas_df = bas_df.apply(pd.to_numeric, errors='coerce')
# Rank the sites for each month based on BAS
ranked_df = bas_df.rank(axis=1, method='min', ascending=False)
# Plot the ranked Babbar Authority Scores using Plotly
fig_ranked_bas = go.Figure()
for column in ranked_df.columns:
fig_ranked_bas.add_trace(go.Scatter(x=ranked_df.index, y=ranked_df[column], mode='lines+markers', name=column))
fig_ranked_bas.update_layout(
title='Monthly Rank of Babbar Authority Scores',
xaxis_title='Date',
yaxis_title='Rank',
yaxis=dict(autorange='reversed'),
hovermode='x'
)
fig_ranked_bas.write_html("ranked_babbar_authority_scores.html")
def main():
confupdate = "N"
api_key = get_api_key()
if os.path.exists("hosts.txt"):
confupdate = input("hosts.txt up to date ? Y/N: ")
if confupdate != "Y":
create_hosts_list()
hosts = []
metrics = {}
with open('hosts.txt', 'r') as f:
for line in f:
hosts.append(line.strip())
for host in hosts:
history = h_history(host, api_key)
if isinstance(history, list):
bas_values = {entry['date']: (entry['babbarAuthorityScore'], convert_scholar_score(entry['scholarScore'])) for entry in history}
else:
bas_values = {date: (data['babbarAuthorityScore'], convert_scholar_score(data['scholarScore'])) for date, data in history.items()}
metrics[host] = bas_values
# Get all unique dates from all hosts
all_dates = sorted({date for values in metrics.values() for date in values.keys()})
# Write to CSV
with open('metrics.csv', 'w', newline='') as csvfile:
fieldnames = ['Date'] + [f'bas_{host}' for host in hosts] + [f'scholar_{host}' for host in hosts]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for date in all_dates:
row = {'Date': date}
for host in hosts:
row[f'bas_{host}'] = metrics.get(host, {}).get(date, (np.nan, np.nan))[0]
row[f'scholar_{host}'] = metrics.get(host, {}).get(date, (np.nan, np.nan))[1]
writer.writerow(row)
plot_metrics('metrics.csv')
plot_ranked_metrics('metrics.csv')
if __name__ == "__main__":
main()Exemple pour l’essai :
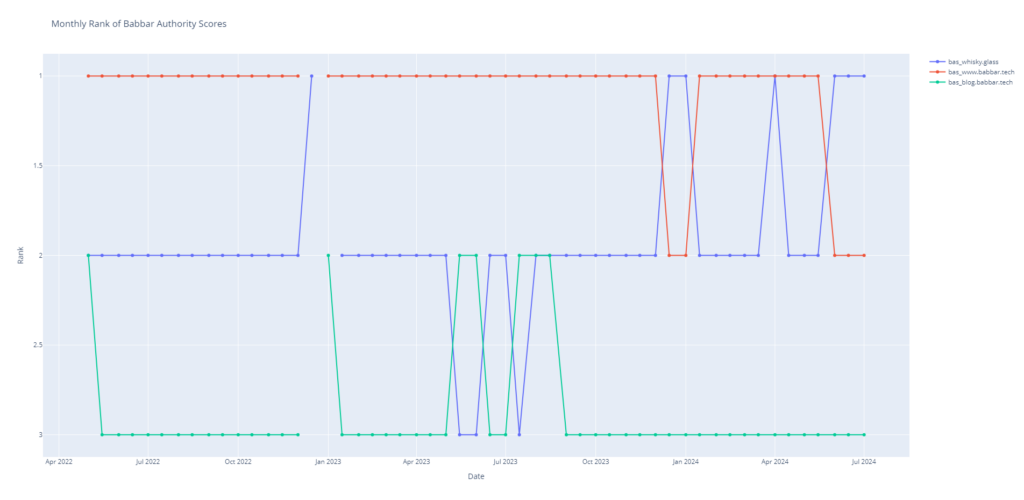
La comparaison du rang des 3 sites selon la métrique du Babbar Authority Score : ici seuls le rouge et le bleu sont vraiment en compétition (si les 3 parlaient du même sujet).
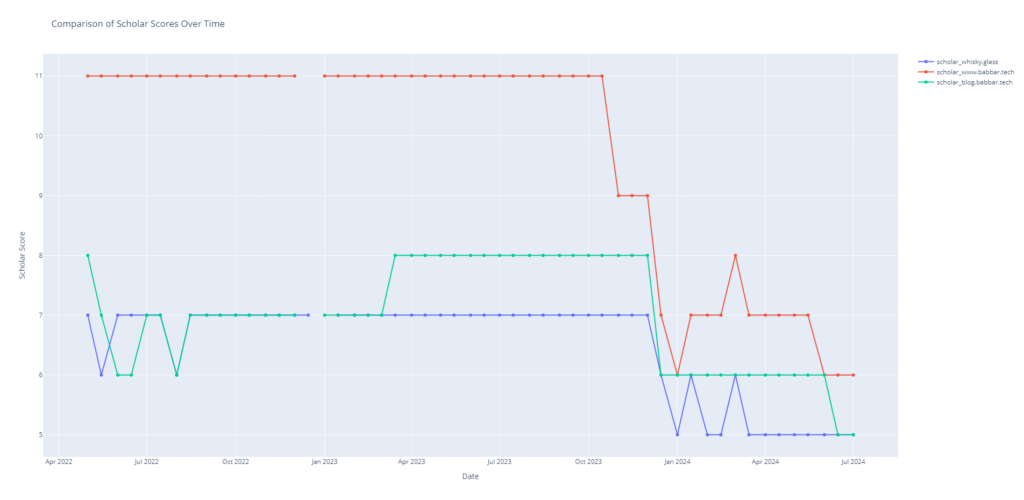
Ici l’historique de la valeur du Scholar Score : on a donc un effet involontaire lié à la baisse de la métrique suite à un nettoyage anti spam de la base.
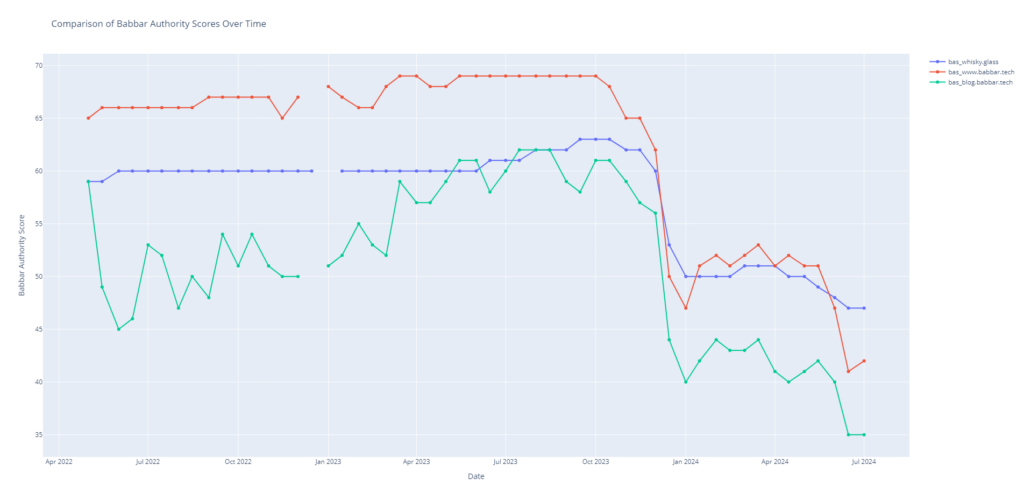
Cet effet est encore plus marqué sur l’historique de la valeur du BAS. Cet effet ne permet pas de comprendre l’évolution réelle des métriques d’autorité dans le contexte du web. C’est pour ça que la comparaison du rang issu de la métrique est plus pertinent, grâce à la comparaison avec les concurrents.
C’est tout pour aujourd’hui, bonne journée !