
L’an dernier, chez Babbar, on a créé le Babbar Dashboard API ou “BDA”. L’une des fonctionnalités essentielles de cet outil utilisable avec Docker, était de pouvoir identifier des concurrents réels et d’extraire les mots clés desdits concurrents sur lesquels notre site ne remontait pas.
Aujourd’hui, je vous propose de refaire cette fonctionnalité en Python, avec un peu de visualisation grâce à mon nouveau package de visualisation préféré : plotly ❤️.
Quelles étapes pour le Content Gap ?
Tout d’abord, on doit définir un host (un site) pour lequel on veut lancer l’outil, et récupérer des informations fournies par Babbar, comme, par exemple, les mots clés du host
# collecte des mots clés d'un host grâce à h_keywords dans BabbarPy.host
def babbar_keywords_to_csv(host, lang, country, start_date, end_date, api_key):
df = h_keywords(host, lang, country, start_date, end_date, api_key)
df.to_csv(f'{host}_keywords.csv')Puis, on récupère les hosts proches sémantiquement du vecteur de notre host principal. Ici pour l’exemple je récupère les 25 premiers, mais on peut en prendre bien plus (ça risque juste de prendre plus de temps).
# récupération des hosts proches et filtre sur le top 25
def fetch_similar_hosts(host, api_key):
data = h_similar(host, api_key)
with open(f'{host}_similar.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, ["host", "similar", "lang", "score"])
writer.writeheader()
for row in data:
row['host'] = host
writer.writerow(row)
similar_hosts_df = pd.DataFrame(data)
return similar_hosts_df
def get_top_similar_hosts(similar_hosts_df, top_limit=25):
top_similar_hosts = similar_hosts_df.head(top_limit)
return top_similar_hostsEnsuite, on va récupérer jusqu’à 20 000 mots clés par host proche (on peut en avoir moins, mais plus, c’est souvent trop pour nos capacités de traitement à posteriori).
# récupération des 20 000 premiers mots clés des hosts proches (moins ou 20 000, pas plus de 20 000)
def collect_keywords_for_similar_hosts(similar_hosts, lang, country, start_date, end_date, api_key):
similar_hosts_keywords = {}
for similar in similar_hosts['similar']:
try:
babbar_keywords_to_csv(similar, lang, country, start_date, end_date, api_key)
keywords_df = pd.read_csv(f'{similar}_keywords.csv')
if len(keywords_df) > 20000:
keywords_df = keywords_df.head(20000)
similar_hosts_keywords[similar] = keywords_df
except Exception as e:
print(f"Error collecting keywords for {similar}: {e}")
return similar_hosts_keywordsEnsuite, on va préparer la visualisation :
On compte les mots clés par host
# classement des hosts par nombre de mots clés
def rank_hosts_by_keyword_count(similar_hosts_keywords):
keyword_counts = {host: len(df) for host, df in similar_hosts_keywords.items()}
ranked_hosts = sorted(keyword_counts.items(), key=lambda item: item[1], reverse=True)
return ranked_hostsOn compte le nombre de mot clé que chaque host a en commun avec le principal
# classement des hosts par nombre de mots clés en commun avec l'host
def common_keywords(host_keywords, similar_hosts_keywords):
common_counts = {}
host_keywords_set = set(host_keywords['keywords'])
for host, keywords_df in similar_hosts_keywords.items():
common_count = len(host_keywords_set.intersection(set(keywords_df['keywords'])))
common_counts[host] = common_count
return common_countsOn crée un graphique pour visualiser tout ça : en abscisse : le taux de proximité entre les hosts, en ordonnée : le nombre de mots clés en commun, et pour la taille des points on va regarder le nombre de mots clés qu’ont les hosts.
# création d'un graphique de type scatter plot : abscisse : proximité, ordonnée : nombre de mots clés en commun, taille des points : nombre de mots clés de l'host
def create_scatter_plot(proximity, common_keywords_count, keyword_counts, directory):
hosts = list(proximity.keys())
scores = list(proximity.values())
common_counts = [common_keywords_count[host] for host in hosts]
sizes = [keyword_counts[host] for host in hosts]
fig = px.scatter(x=scores, y=common_counts, size=sizes, hover_name=hosts,
labels={'x': 'Proximity Score', 'y': 'Common Keywords Count'},
title='Scatter Plot of Hosts by Proximity and Common Keywords')
plot_path = os.path.join(directory, "competition_viz.html")
fig.write_html(plot_path)
fig.show()Enfin je rassemble les listes de mots clés de tous les concurrents et du site principal pour faire une sorte d’index complet, duquel je retire les mots clés que le site principal a pour créer le Content Gap.
def assemble_keywords_files(directory):
all_keywords_df = pd.DataFrame()
for file in os.listdir(directory):
if file.endswith("_keywords.csv"):
file_path = os.path.join(directory, file)
df = pd.read_csv(file_path)
all_keywords_df = pd.concat([all_keywords_df, df], ignore_index=True)
all_keywords_file = os.path.join(directory, "all_keywords.csv")
all_keywords_df.to_csv(all_keywords_file, index=False)
return all_keywords_file
def create_gap_file(all_keywords_file, host_keywords_file, directory):
all_keywords_df = pd.read_csv(all_keywords_file)
host_keywords_df = pd.read_csv(host_keywords_file)
host_keywords_set = set(host_keywords_df['keywords'])
gap_df = all_keywords_df[~all_keywords_df['keywords'].isin(host_keywords_set)]
gap_file = os.path.join(directory, "GAP.csv")
gap_df.to_csv(gap_file, index=False)
return gap_fileLe fichier résultant est purement un Content Gap, même si techniquement, un peu de travail reste à faire pour affiner le contenu que vous pouvez adresser.
Les prérequis techniques :
J’utilise les bibliothèques suivantes :
datetime, os, configparser, pandas, csv, BabbarPy (une création personnelle), plotly et shutil.
Et voilà le code :
Quelques précisions : pour plus de clarté, je crée des dossiers avec les noms des hosts principaux, et je mets les csv et la visualisation créée dans un dossier ContentGap
import datetime
import os
import configparser
import pandas as pd
import csv
from BabbarPy.host import h_keywords, h_similar
import plotly.express as px
import shutil
def babbar_keywords_to_csv(host, lang, country, start_date, end_date, api_key):
df = h_keywords(host, lang, country, start_date, end_date, api_key)
df.to_csv(f'{host}_keywords.csv')
def get_api_key():
config = configparser.ConfigParser()
if not os.path.exists('config.ini') or not config.read('config.ini') or 'API' not in config or 'api_key' not in config['API']:
api_key = input("Entrez votre clé API: ")
config['API'] = {'api_key': api_key}
with open('config.ini', 'w') as configfile:
config.write(configfile)
return api_key
else:
return config['API']['api_key']
def collect_keywords(host, lang, country, start_date, end_date, api_key):
babbar_keywords_to_csv(host, lang, country, start_date, end_date, api_key)
keywords_df = pd.read_csv(f'{host}_keywords.csv')
return keywords_df
def fetch_similar_hosts(host, api_key):
data = h_similar(host, api_key)
with open(f'{host}_similar.csv', 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, ["host", "similar", "lang", "score"])
writer.writeheader()
for row in data:
row['host'] = host
writer.writerow(row)
similar_hosts_df = pd.DataFrame(data)
return similar_hosts_df
def get_top_similar_hosts(similar_hosts_df, top_limit=25):
top_similar_hosts = similar_hosts_df.head(top_limit)
return top_similar_hosts
def collect_keywords_for_similar_hosts(similar_hosts, lang, country, start_date, end_date, api_key):
similar_hosts_keywords = {}
for similar in similar_hosts['similar']:
try:
babbar_keywords_to_csv(similar, lang, country, start_date, end_date, api_key)
keywords_df = pd.read_csv(f'{similar}_keywords.csv')
if len(keywords_df) > 20000:
keywords_df = keywords_df.head(20000)
similar_hosts_keywords[similar] = keywords_df
except Exception as e:
print(f"Error collecting keywords for {similar}: {e}")
return similar_hosts_keywords
def rank_hosts_by_keyword_count(similar_hosts_keywords):
keyword_counts = {host: len(df) for host, df in similar_hosts_keywords.items()}
ranked_hosts = sorted(keyword_counts.items(), key=lambda item: item[1], reverse=True)
return ranked_hosts
def common_keywords(host_keywords, similar_hosts_keywords):
common_counts = {}
host_keywords_set = set(host_keywords['keywords'])
for host, keywords_df in similar_hosts_keywords.items():
common_count = len(host_keywords_set.intersection(set(keywords_df['keywords'])))
common_counts[host] = common_count
return common_counts
def create_hosts_list():
hosts = []
while True:
host = input("Veuillez entrer le host à vérifier (ou appuyez sur entrée pour terminer) : ")
if host == '':
break
hosts.append(host)
with open('hosts.txt', 'w') as f:
for host in hosts:
f.write(f"{host}\n")
def create_directory_for_host(host):
directory = f"./{host}/ContentGap/"
if not os.path.exists(directory):
os.makedirs(directory)
return directory
def move_files_to_directory(directory, files):
for file in files:
if os.path.exists(file):
base_filename = os.path.basename(file)
destination = os.path.join(directory, base_filename)
if os.path.exists(destination):
os.remove(destination)
shutil.move(file, directory)
def create_scatter_plot(proximity, common_keywords_count, keyword_counts, directory):
hosts = list(proximity.keys())
scores = list(proximity.values())
common_counts = [common_keywords_count[host] for host in hosts]
sizes = [keyword_counts[host] for host in hosts]
fig = px.scatter(x=scores, y=common_counts, size=sizes, hover_name=hosts,
labels={'x': 'Proximity Score', 'y': 'Common Keywords Count'},
title='Scatter Plot of Hosts by Proximity and Common Keywords')
plot_path = os.path.join(directory, "competition_viz.html")
fig.write_html(plot_path)
fig.show()
def create_gap_file(all_keywords_file, host_keywords_file, directory):
all_keywords_df = pd.read_csv(all_keywords_file)
host_keywords_df = pd.read_csv(host_keywords_file)
host_keywords_set = set(host_keywords_df['keywords'])
gap_df = all_keywords_df[~all_keywords_df['keywords'].isin(host_keywords_set)]
gap_file = os.path.join(directory, "GAP.csv")
gap_df.to_csv(gap_file, index=False)
return gap_file
def assemble_keywords_files(directory):
all_keywords_df = pd.DataFrame()
for file in os.listdir(directory):
if file.endswith("_keywords.csv"):
file_path = os.path.join(directory, file)
df = pd.read_csv(file_path)
all_keywords_df = pd.concat([all_keywords_df, df], ignore_index=True)
all_keywords_file = os.path.join(directory, "all_keywords.csv")
all_keywords_df.to_csv(all_keywords_file, index=False)
return all_keywords_file
def main():
default_vals = input("default values: lang = 'fr', country = 'FR', date = today - 2 weeks : OK ? (y/n) ")
if default_vals.lower() != 'y':
lang = input("Enter the language code (e.g. 'en'): ")
country = input("Enter the country code (e.g. 'us'): ").capitalize()
date_formatted = input("Enter the start date (YYYY-MM-DD): ")
else:
lang = 'fr'
country = 'FR'
date_start = datetime.date.today() - datetime.timedelta(weeks=2)
date_formatted = date_start.strftime("%Y-%m-%d")
api_key = get_api_key()
confupdate = "N"
if os.path.exists("hosts.txt"):
confupdate = input("hosts.txt up to date ? Y/N: ")
if confupdate != "Y":
create_hosts_list()
with open('hosts.txt', 'r') as file:
hosts = file.readlines()
for host in hosts:
host = host.strip()
directory = create_directory_for_host(host)
host_keywords = collect_keywords(host, lang, country, date_formatted, date_formatted, api_key)
similar_hosts_df = fetch_similar_hosts(host, api_key)
top_similar_hosts = get_top_similar_hosts(similar_hosts_df)
similar_hosts_keywords = collect_keywords_for_similar_hosts(top_similar_hosts, lang, country, date_formatted, date_formatted, api_key)
ranked_by_keyword_count = rank_hosts_by_keyword_count(similar_hosts_keywords)
common_keywords_count = common_keywords(host_keywords, similar_hosts_keywords)
proximity = {row['similar']: row['score'] for _, row in top_similar_hosts.iterrows()}
keyword_counts = {host: count for host, count in ranked_by_keyword_count}
files_to_move = [f"{host}_keywords.csv", f"{host}_similar.csv"] + [f"{similar}_keywords.csv" for similar in top_similar_hosts['similar']]
move_files_to_directory(directory, files_to_move)
all_keywords_file = assemble_keywords_files(directory)
create_gap_file(all_keywords_file, os.path.join(directory, f"{host}_keywords.csv"), directory)
create_scatter_plot(proximity, common_keywords_count, keyword_counts, directory)
if __name__ == "__main__":
main()Quelques exemples de visualisation :
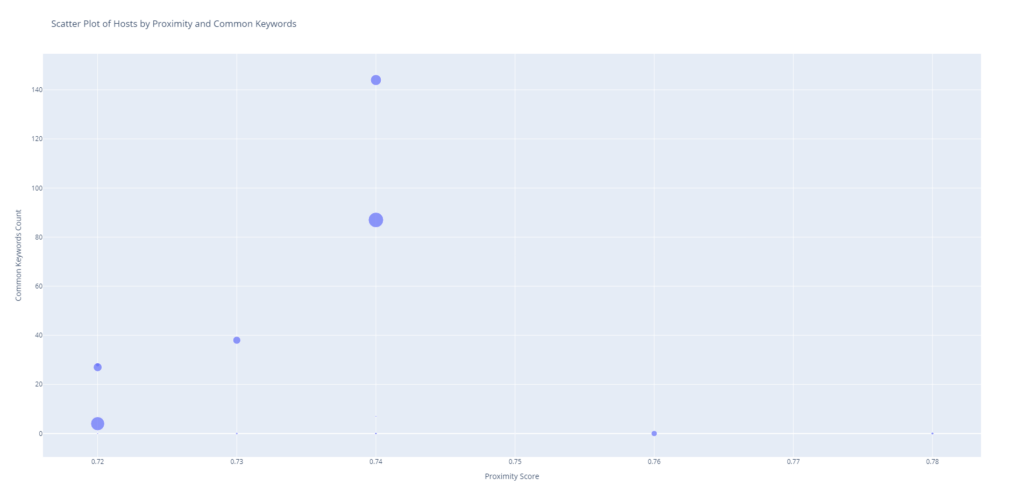
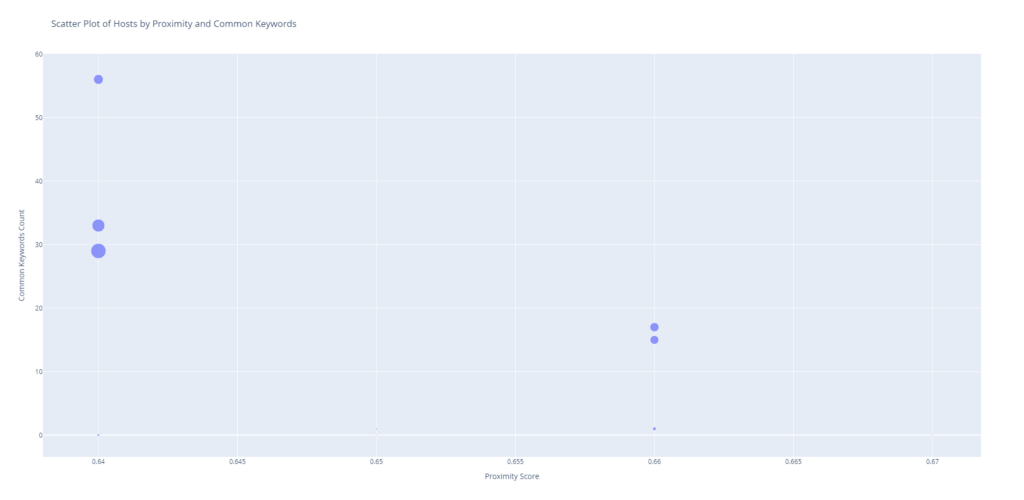
En bref, une visualisation pratique pour le professionnel SEO qui va identifier les concurrents, et obtenir des listes de mots clés à adresser à partir de ces concurrents.
C’est tout pour aujourd’hui, bonne journée !